Why We Are Building "Codatum": A Data Analysis Tool from an Engineer's Perspective
Contents
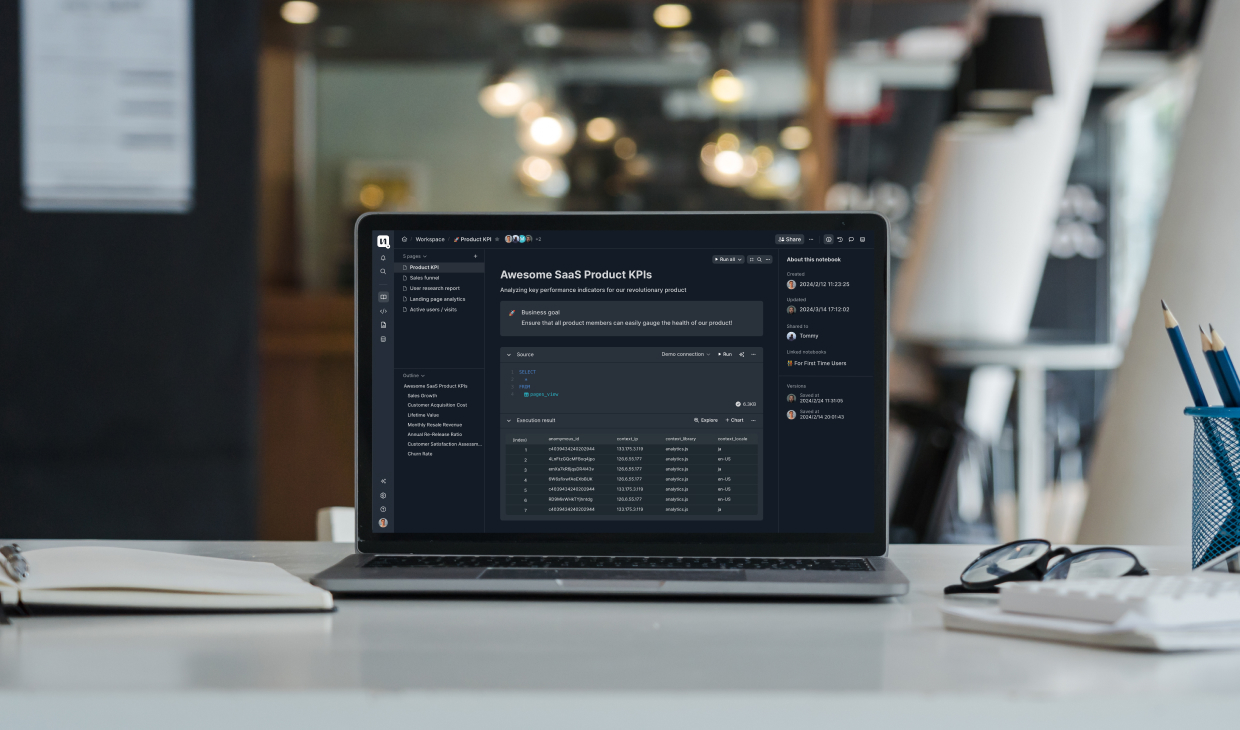
Hello. We are the team developing a data analysis tool called Codatum. Today, I'd like to talk about why we started this project and the background behind it.
15 Years of Experience Working with Data
For nearly 15 years, I've been involved in data processing and analysis related to product development—first as a researcher, then as an engineer, product manager, and eventually as an executive. I've created queries for report screens, analyzed user behavior, and examined logs during incident responses. I've also utilized data when analyzing company costs and SaaS usage.
At a Japanese technology company processing over 2+ PB of data in BigQuery, where Codatum was born from our daily data analysis experiences, my work in centralizing and analyzing various types of data provided deep insights for the analysis process.
To leverage this importance and solve challenges, I've used a wide array of tools: Jupyter Notebook, Google Colab, BigQuery's console, Mode Analytics, Looker, Domo, Google Spreadsheet, or embedding into applications using Node or Golang, among others. Even now, many of these tools are indispensable to us and play crucial roles in our company (especially Looker, Mode Analytics, and Google Spreadsheet have been constantly helpful).
However, there are areas where I strongly feel challenges.
Limited Users, Builders, and Maintainers of BI Tools
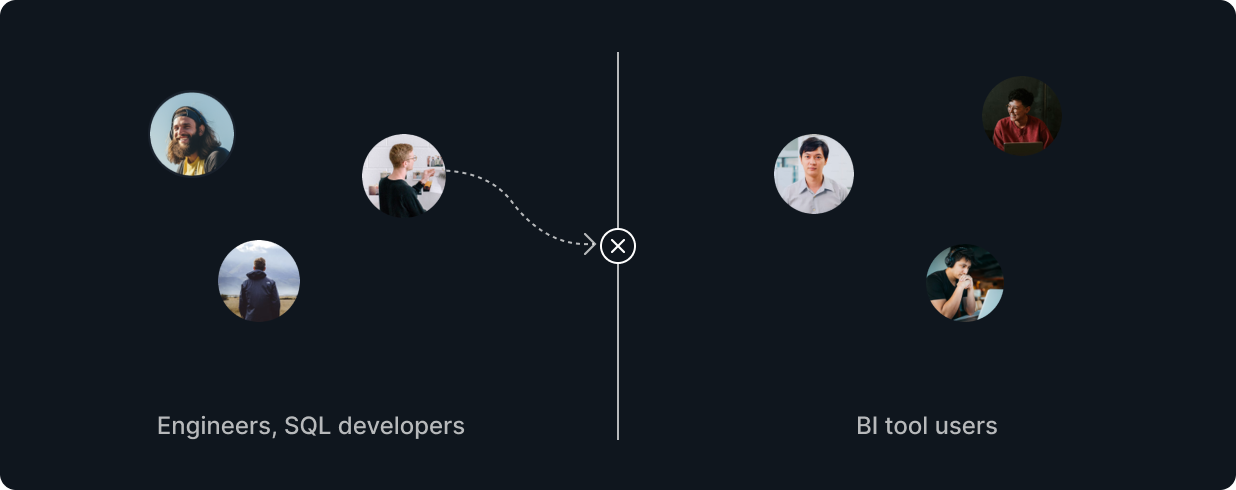
There are many people in the company, including engineers, who can write SQL or want to write SQL. However, while they may use BI tools when asked, they rarely use them proactively. They keep their distance, seeing them as "tools unrelated to us." Why is that?
Inability to Assess Data Freshness and Reliability at a Glance
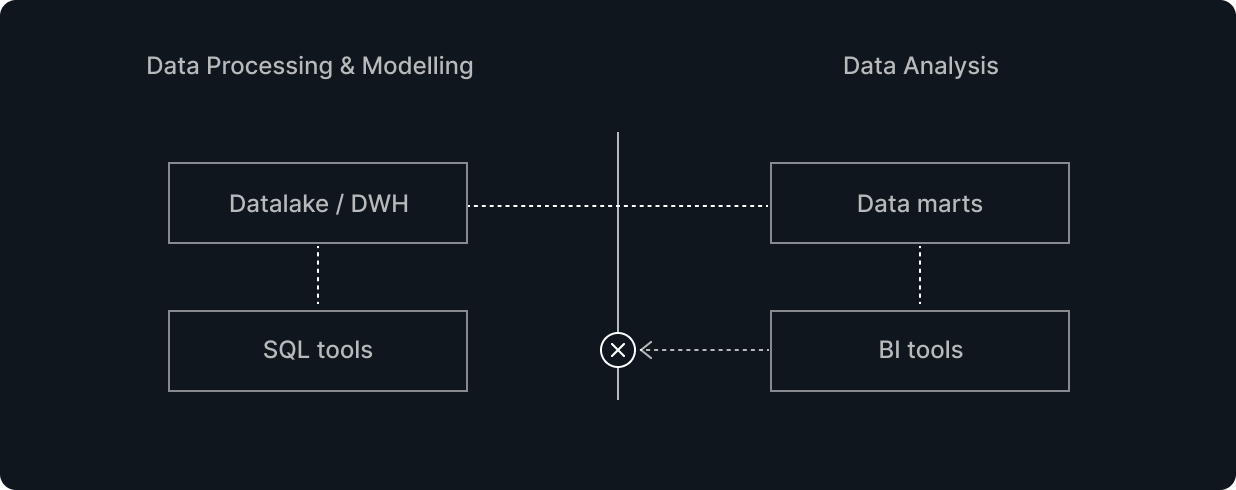
When data becomes outdated or incorrect, or when you want to analyze with a new perspective, often the worlds of data processing/modeling and analysis are separated, and responsibilities are different, making it impossible to confirm everything seamlessly. Also, since you cannot confirm, you cannot update.
This involves issues with data synchronization and pipelines across multiple tools, and problems of black-boxing due to tools' unique GUIs and DSLs.
Both are too significant to ignore. There's no need to mention here that data can provide invaluable insights for the company. It's very unfortunate, or perhaps even sad, that the people who would be most skilled at leveraging this are keeping their distance, or that the data itself is in an unreliable state.
Challenges Behind the Tools from an Engineer's Perspective

I believe there are several reasons behind these challenges:
Lock-in, Learning Costs, Constraints, and Black-boxing Due to Tools' Unique GUIs and DSLs
While many people may not resist paying learning costs, they do resist acquiring knowledge that can only be used with that tool. They also resist learning tools' unique GUIs and DSLs that limit freedom.
Data Definitions, Synchronization, and Pipelines Spanning Multiple Tools/Languages
The separation of data processing/modeling and analysis leads to a loss of data freshness and reliability.
Not Engineer-Friendly
The third reason is quite simple but cannot be ignored. Engineers love code-first, keyboard-based UIs.
These seem to bring common concerns from the world of product development into the realm of data processing and analysis. Hating being locked-in, disliking black-boxing, eliminating redundancy as much as possible, always wanting to keep the data that's "truly correct" at hand, and desiring to be open to everyone—that's the motivation.
How We Are Trying to Solve It
To address these issues, we are developing a tool with the following features:
Utilizing Common Languages
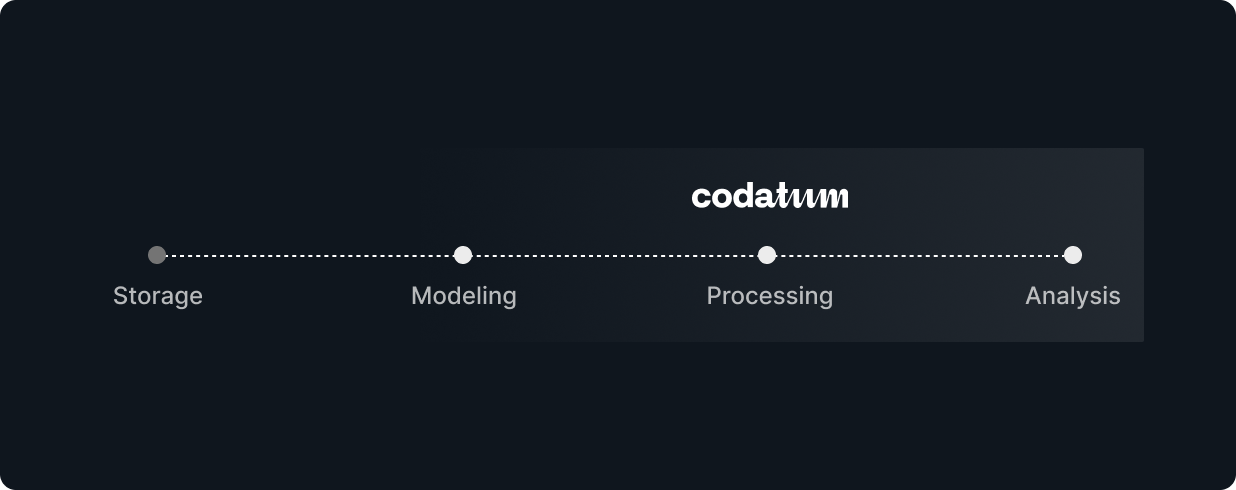
Instead of unique GUIs or DSL-based systems, we aim to make it so that anyone can use it immediately when needed by basing it on SQL and Markdown (Block Editor) without hiding them. We also aim to prevent black-boxing by allowing anyone to read and comment on what others have created.
Handling Everything Seamlessly in the Same Language
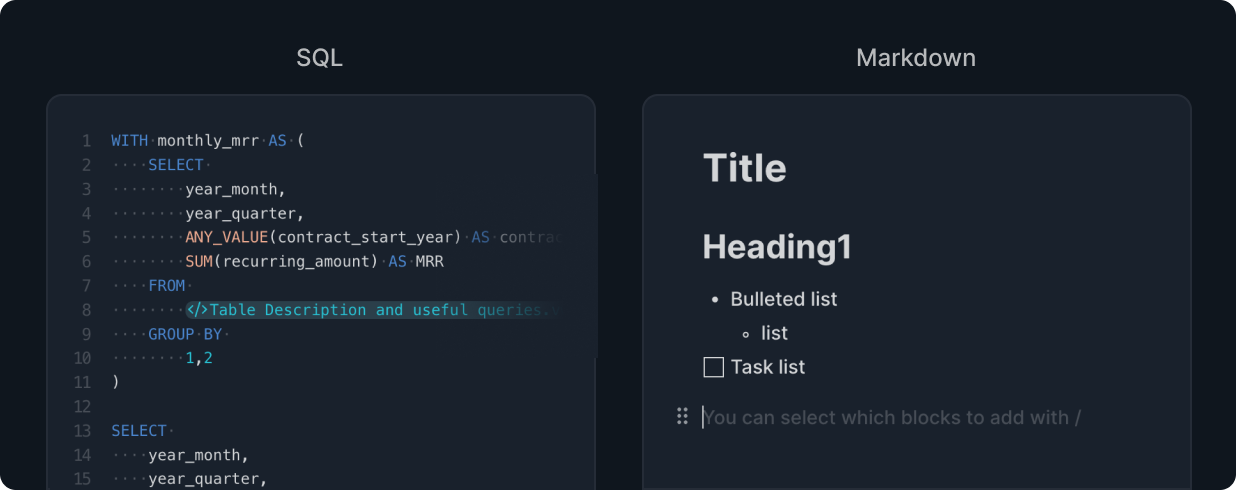
By providing features like SQL splitting and referencing, and offering query saving and cataloging functions, we enable seamless data processing, exploration, and partitioning based on SQL. This helps maintain data freshness and reliability as much as possible.
Code-First UI Design
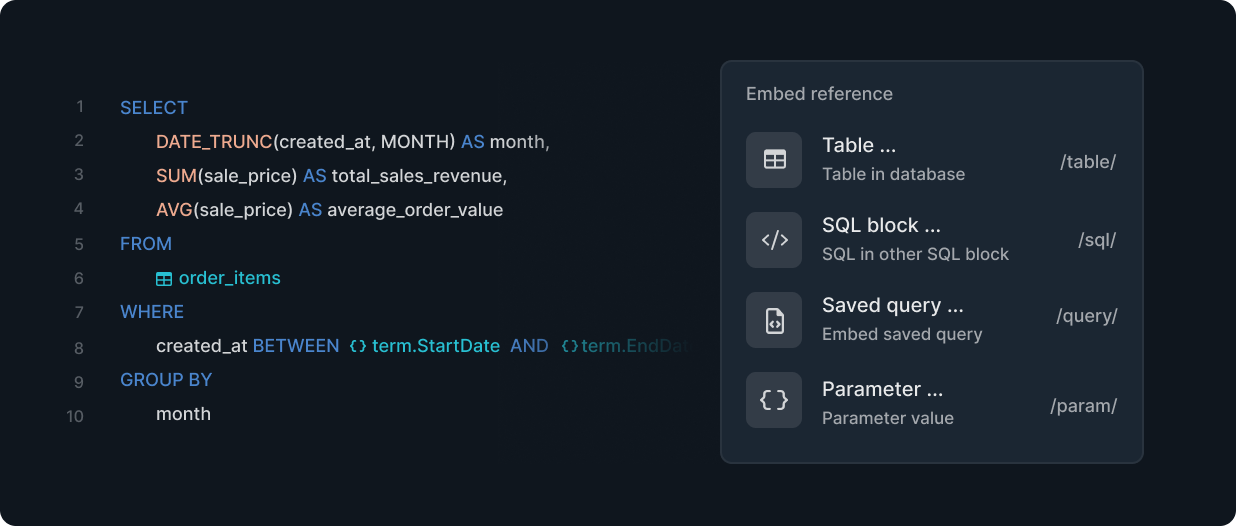
By creating a code-first, keyboard-based UI, we aim to develop a tool that engineers will want to use themselves.
Besides these, issues with SQL itself and permission management in data analysis are also within our scope, but we'll omit them here.
The World We Aim For
Our goal is to cultivate a data-driven culture throughout the organization, beyond merely providing tools. Through Codatum, we want to create an environment where engineers and SQL experts—those who can write code—actively participate in data analysis and fully unleash their capabilities.
Also, in recent years, there is a general movement to have many members within a company learn SQL. With significant advancements in LLMs (Large Language Models), it has become possible to ask AI to generate or modify code. At Codatum, we are also strongly integrating with LLMs in various areas. By leveraging the help of LLMs or looking at existing code from experts, we aim to provide an environment where beginners can become "people who can write code and do data analysis."
Codatum aims to be the best data analysis and BI tool that "makes people who write code happy" and "increases the number of people who write code." We hope to evolve our product together with those who share this vision.
Please try Codatum. And let us hear your voice. Let's create a data-driven future together.